Monitoring
The objective is relevance: timely, accurate, and actionable.
Monitoring integrates automation (machines) and communication (humans). It completes a feedback loop between systems and people. Monitoring ensures Operations continues to run and run smoothly. Far too often monitoring is not done well. Development and Operations are insufficiently responsive to problems in their offerings and have too frequently allowed their customers to identify issues. Customers report urgent problems. Teams immediately jump into to reaction mode, and run around putting out the fire, saving the day from their own lack of effective monitoring. That’s crazy making. Effective monitoring is crucial to the mental health of your organization. A DevOps culture cares about mental health and staying sane.
Too often monitoring is just a mess. Important, but non-critical systems are not monitored at all. For systems that are monitored, the monitoring is often tuned poorly. Monitoring spams non-urgent alerts. When it comes to the ratio of signal-to-noise, it’s typically a distracting amount of noise. Alerts that need action are lost. The refrain of managers of bad monitoring is heard once again, “the system generated an alert, but we did not see it.” On the Development side they have similar problems. For example, regular feedback on the state of the build and test can be lacking. Test reports are incomplete or difficult to access. Attention needs to be paid to properly configuring monitoring systems.
Timely
Monitoring needs to be timely, accurate and actionable. Timely alerts are sent at the right time. The right time is not always immediately when the issue is identified. For example, it is important to monitor test systems. Consuming all the allocated disk space on a test system may disrupt development. Disk alerts on test systems are useful for keeping Developers working without interruption. But if you're sending text messages to your Ops staff in the middle of the night for a disk alert on a test system, you’re not doing it right. That’s not a timely alert. You don't need to wake your Ops staff to fix a non-critical issue on a test system. A timely alert would be during work hours.
The best type of alert is predictive. They warn you of an impending problem. A failure hasn’t occurred yet, but without action, one is likely. Disk usage warnings fall into this category. You need alerts that tell you something is broken. That type of monitoring cannot be ignored. But the deeper you can get your monitoring into your system, so failures can be anticipated, that makes for the most useful monitoring.
Accurate
Alerts need to be accurate! The bane of monitoring is false alerts. No one enjoys a wake up in the middle of the night responding to pages from a system that is in fact working just fine.
Actionable
Alerts must be actionable. An alert that is incomprehensible or lacks an expected response is either noise or worse—something needs attention, but it is getting neglected because the recipient of the alert doesn’t know how to respond. Actionable monitoring has a lot to do with preparation. When you get an alert, you need to know how to respond. Alerts need to be correctly categorized. Many alerts require some technical action. Other alerts require communicating to customers and/or vendors. Casualty procedures or use cases need to be well documented and available when the alert sounds.
Monitoring is about knowing your systems and the state they are in. Without monitoring you’re in a bad place. You’re that infamous chicken with its head cutoff, still running around… but already dead.
Monitoring Challenges
Meaningful monitoring requires a careful eye. It requires looking at the object of your concern from a multitude of perspectives. Ops, Dev, management and users all have their own point of view. While each of these views is important in and of themselves, the sum of these perspectives is greater than the parts. The picture develops as more perspectives are processed.
As an example of the importance of considering as many perspectives as possible, take the Escher print below. Is it a picture of geese or fish? It is both at the same time. You need to look at the negative space as well as the positive space; one reveals the other. To see the true picture you must recognize how differing pieces fit together.

Figure 15: Positive and negative space
The larger and more complicated the object of your attention is, the more perspectives you need. Do you remember the story of the seven blind mice describing an elephant? The view of any one mouse was not enough to understand the elephant they were all looking at. And how about the old adage about missing the forest for the trees? The dissonance between our perception and the reality of things is fascinating. I could go on and on with these examples, but let’s move on to some other monitoring challenges.
You can get carried away with monitoring. If you “monitor everything” you will likely get overrun! Getting inundated with low-grade notices from your monitoring system is a very good way to miss the alerts that you really need to pay attention to. False alerts and alerts for non-urgent conditions pave the path to shutting out what is important. Reducing the noise to get the signal is a must!
Even when monitoring is performing well, challenges remain. Our brains have a propensity to form patterns according to expectations rather than actual data. This picture was used to test the perception of medical students examining chest x-rays. A whopping 83% of test subjects missed the gorilla in the picture. But you saw it right?
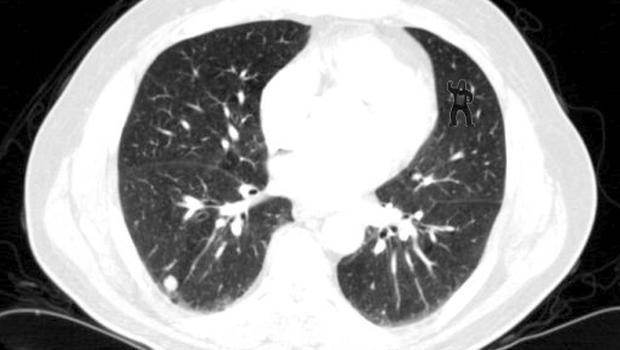
Figure 16: What gorilla?
All of these challenges are significant, and typical Ops monitoring has not been up to the task. The worst part of what has passed as Ops monitoring, is the extent that Ops unintentionally relies on their customers to identify problems. With poor monitoring Ops teams put their customers in the position of having to report important problems; like the site is so slow it is unusable!
To effectively manage an application for the benefit of all constituents, monitoring needs to simulate all your stakeholders’ points of view. Many customer issues can be handled effectively. Bugs, training and workflow issues can be managed with an on-point support team. But when your customers have to tell you about performance or availability problems, your business is in trouble. This is the worst. Your customer does not care about your technical issues. They want to get their work done. By the time a customer opens a ticket to complain about not being able to do their work, you may have already lost any chance of a service renewal. The damage increases exponentially with the mission criticality of the service you are providing. If your customers are working in real-time like medical service providers, sellers in on-line auctions or whatever they are doing that is really important to them, and your application is not available? You are toast. Monitoring needs to be timely, accurate and actionable.